Welcome to
__
(___()'`; www.nerdondon.com
/, /`
\\"--\\
^ its a huge gou. get it? think Chinese :).
..."gou" means dog in Chinese but also hugo for the blog plaform.
Anyway, the content will generally be techinical and about software engineering
but I might throw in some random topics here and there.
Linux dne.nerdondon.com 2.0.0-1-arm64
Last login: (lol how do you do this with hugo?)
Chain replication is a leaderless replication mechanism. It is a mechanism I first came in contact
with when I worked at AWS. For now, this is just a bunch of references I found enlightening.
These are just some of my notes and references on Bloom filters while doing research for building an
LSM tree based database.
Notes
A Bloom filter is a probablistic data structure that allows checks for set membership. These
checks for set membership can return false positives but will never produce false negatives. More
clearly: “if a negative match is returned, the element is guaranteed not to be a member of the
set” (Alex Petrov - Database Internals).
Used to lower I/O costs incurred by the tiered structure of LSM-trees
These are just some of my notes and references from implementing a skip list in Rust. Creating a
skip list implementation that has concurrency features is my personal intro project to Rust so there
will also be some notes on lock-free and wait-free techniques. The overarching goal is to utilize
this skip list as the in-memory component of an LSM-tree based storage engine, that I will maybe,
hopefully, aspirationally, try to make. LevelDB in Rust if you will.
Notes
Used as the in-memory component of LevelDB’s log structured merge tree (LSM tree) implementation
Skip list vs self-balancing search trees (e.g. Red-black trees)
A skip list is more amenable to concurrency because less nodes are required to be updated during
an insert
On update, a self-balancing tree may require multiple ancestors to be changed when the balancing
operations (e.g. rotations in a Red-black tree)
LevelDB is doesn’t have concurrent writes? Source appears to require an external lock mechanism
for writes.
When used as the in-memory component of an LSM tree, the skip list should support sorting by
reverse chronological order. This can be done by having a synthetic key with a timestamp/revision
number or via reverse iteration by back pointers. This is because the LSM tree is an append only
structure.
Using an RwLock can become a bottleneck for operations with a short critical section. You will
effectively benchmarking the time it takes to lock and unlock.
Log-structured merge-trees (LSM trees) are a data structure used for write-heavy workloads.
LSM trees are the basis of many NoSQL/NewSQL databases e.g. Cassandra, LevelDB, RocksDB, etc.
Because of their optimization towards write-heavy workloads, LSM trees also lend themselves to
time series databases like InfluxDB.
Whereas B+ trees (used in such storage engines as InnoDB) must maintain their structure via random
writes, LSM trees gain their write speed by being structured in such a way as to take advantage of
sequential writes.
To lend itself to sequential writes, the LSM tree is an append-only structure.
At a high level, an LSM tree is composed of different levels/tiers where each level is a different
individual data structure that each have different backing storage formats that are increasingly
slower.
For example: tier 0 of an LSM tree can be backed by RAM, tier 1 by SSD, and tier 2 by spinning
drives.
This tiered storage architecture also works nicely with cloud native trend, where each tier of
storage can be concretely backed by a different cloud offering depending on application needs.
Data is first written to the first tier and data is asynchronously pushed down to lower layers
as the first tier fills. Reads are performed similarly.
Structure
Although referred to as a data structure, an LSM tree can more accurately be described as a
technique for composing multiple data structures to achieve desired performance characteristics.
Despite the LSM paper saying that “[a]n LSM-tree is composed of two or more tree-like component
data structures”, the components that make up an LSM tree do not actually have to be tree-like at
all.
They can be any sorted data structure, which allows you to tune performance characteristics of
the LSM tree tiers to your application’s requirements.
As an example, LevelDB uses a skiplist in its first tier. The original paper suggests a (2,3)
tree or an AVL tree in the first tier and a B tree in the second.
Fun aside, Redis utilizes skiplists as the backing data structure for their sorted set data type
The canonical example of an LSM tree is a two-tiered structure composed of an in-memory tier and a
on-disk tier. The in-memory tier is usually referred to as a memtable. Modern on-disk component
examples utilize a structure inspired by Google’s BigTable called an SSTable (Sorted Strings
Table).
An interesting point from John Pradeep Vincent on runtimes with GC - “For java implementations,
the memtable is usually stored off-heap (direct memory) to avoid GC load.”
Memtable
As mentioned above, this is the primary in-memory component of an LSM tree.
Since this first point of contact for writes is in-memory, a storage engine would still utilize a
write ahead log (WAL) to ensure durability.
Once this tier is filled to a certain size threshold, its contents are flushed to the next tier of
the LSM tree.
SSTable (Sorted Strings Table)
SSTables are just one implementation for the on-disk tier of an LSM tree but are pretty popular in
existing literature, so here’s some SSTable specific notes.
SSTables, as their name implies, stores data sorted by their key. It is a file (or multiple files)
that generally have two parts: an index block and a data block.
The index block stores mappings from keys to offsets within the data block
A new SSTable (file or set of files) is created when the contents of the memtable are flushed or
when a compaction operation occurs.
Because these SStables are effectively dumps of the memtable, there can be overlapping key ranges
in different SSTable files. In order to improve read performance, a compaction operation is
occasionally conducted.
As compaction operations occur and new SSTables are continually created from memtable flushes, a
layered structure begins to manifest from the SSTables where each layer has more recent data and
shadows the lower layers. Keeping the layers shallow is important to maintaining the performance
of the LSM tree and hence compaction is a key component of the LSM tree.
Operations
Read
With the above structure of a memtable and SSTables, the worst-case read path would be: memtable
-> a linear scan–in reverse chronological order–of each level of SSTables
To augement the speed of reads, there are a couple of data structures that are commonly introduced
into the read path. Two of them being an extra index on top of the SSTables (different from the
index file specific to a single SSTable) and a Bloom filter.
John Pradeep Vincent puts it best for a Bloom filter: due to the false positives being possible
“the presence of a bloom filter improves the read performance for keys that are missing in the
system but for the keys that are present in the system, the read is still expensive as we have
to look into the memtable, index and the SSTable.”
In terms of general database tricks to make read and write paths faster, memory mapping the disk
files or using a buffer pool are also techiniques that can be utilized
Write
Writes always go to the in-memory component first and can trigger a flush of the memory file
contents to disk.
With the auxiliary data structures mentioned above, writes would also need to upadate the WAL, the
Bloom filter, and the index for SSTables.
Again the LSM tree is an append only structure, so updates will write an updated entry that will
shadow the previous entry and deletions will write a tombstone indicating item deletion.
Compaction
Compaction for an LSM tree is often compared to the garbage collector (GC) featured in many
programming languages.
Just as with garbage collection, there are myriad strategies that can be implemented for
compaction. For example: concurrent/asynchronous vs synchronous, manually triggered vs threshold
triggered.
Recalling that an LSM tree is an append-only structure, compaction is then critical for cleaning
up stale records and deletion tombstones.
Other topics for expansion
Potential topics that I would like to expand on if I revisit this post or ideas for subsequent
posts.
Discussion on read and write amplication and comparing and contrasting those values for LSM trees
vs B trees
Expand on Niv Dayan video on knobs to turn to change scaling properties of an LSM tree
implementation
Cassandra and BigTable SSTable implementation details
Compare against update in place data structures like a copy-on-write (CoW) tree
Some notes from the Envoy Internals Deep Dive talk by Matt Klein. The talk was given at KubeCon
EU 2018. Watch on YouTube here.
Actual Notes :D
Architecture
Envoy is designed with an out of process architecture specifically to address the polyglot nature
of microservices
At its core, Envoy is a byte proxy. This gives it extensibility to supoort a multitude of
protocols.
Create with versatility from the start so that Envoy can act as service, middle, and edge proxy
Hot restart is key feature
One part of Envoy is built as a pipeline with filters as building blocks. Filters are extension
points where users can add functionality.
The other part of the architecture is where the central management functionality lives. Things
like the cluster/service managers or stats engine.
The prevailing school of thought for proxies before the 2000s was to have serve a single
connection per thread. Envoy is takes a different approach where it serves multiple connections
per thread via an event loop.
The “main” thread of Envoy handles the management functionality and worker threads handle the
connections and filter pipeline. The key to keeping Envoy simple is the latter part of the
previous statement. It means that worker threads do not have to communicate with each other and
only have to acquire locks in a small set of cases.
Read-Copy-Update (RCU) is used to govern parallelization within Envoy. “Designed for read heavy,
write infrequent workloads”. Helps reduce the need for locking by making the read path lock free.
Envoy keeps a vector pointers in thread local storage (TLS) that is mirrored across the main and
worker threads. RCU is used to update slots in the vector and posts messages to worker threads to
update information e.g. route tables.
Hot Restarts
“Full binary reload without dropping any connections”
Allow two processes of Envoy to run at the same time and utilize a shared memory region. Stats and
locks are stored here.
The two proceses communicate through an RPC protocol over Unix domain sockets (UDS) and perform
socket passing. After the second Envoy process spins up, it will communicate that it is good to go
and the first process will begin to drain connections.
Stats
There’s a 2 level caching mechanism for stats. There is a TLS cache, a central cache on the main
thread, and the actual entries either in shared memory or in process memory.
Some notes from the V8 internals for JavaScript developers? talk by Mathias Bynens. The talk was
given at JsConf AU 2018. Watch on YouTube here. This
talk focuses on arrays and JS engine optimizations around array operations.
Actual Notes :D
Element kinds
Arrays can be described by the types of elements they hold (3 types in V8) and whether or not they
are packed.
The three types are SMI, DOUBLE, and ELEMENTS. SMI is a subset of DOUBLE and DOUBLE is a subset
of ELEMENTS. SMI here stands for small integers.
An array and it’s element types are described together as the following regex
(PACKED | HOLEY)(_SMI | _DOUBLE)?_ELEMENTS
For example, PACKED_SMI_ELEMENTS or HOLEY_ELEMENTS
To be clear, a “holey” array is also known as a sparse array
Packed arrays are more performant than holey arrays
This is because V8 not only has to perform bounds checks on your array index, it must also check
the prototype chain for the index.
For example, suppose you are querying arr[8] and arr is holey with length 9 and arr[8] is
undefined. V8 will check if the property 8 exists on arr with hasOwnProperty(arr, '8'). This
check will return false so V8 must go the next level up the prototype chain and check
hasOwnProperty(Array.protoype, '8'). This will return false as well. This check goes on until
the prototype chain ends. This is a lot of work that the runtime has to do especially if you
consider that JavaScript arrays can be subclassed.
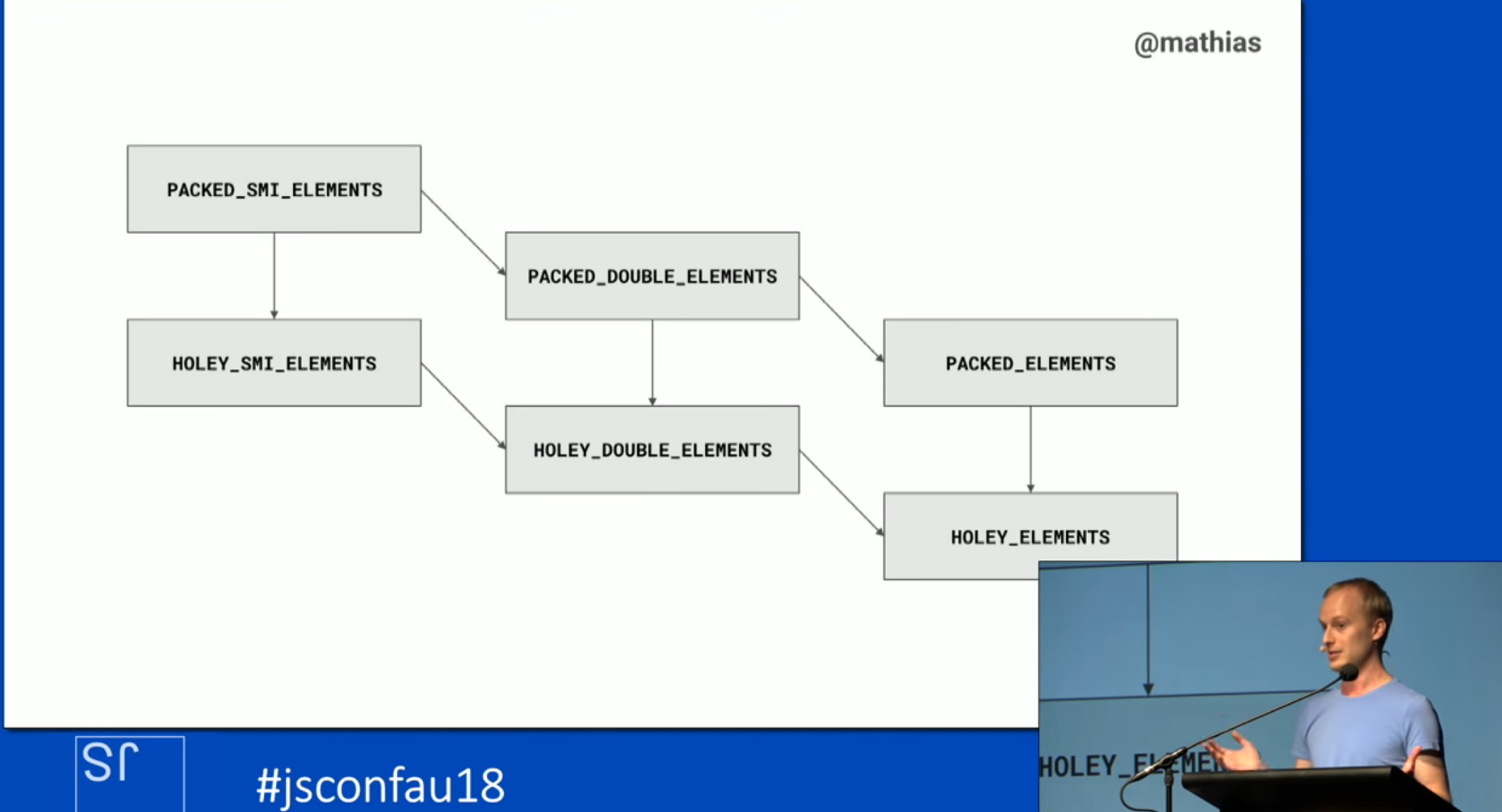
Transitioning between element kinds
Delving deeper into how the different element kinds relate to each other, V8 will classify an
empty array by the simplest classification i.e. SMI. If you push a floating point number onto a
SMI array, the array will be reclassified to DOUBLE. The analogous re-classification will occur if
you then push an object on to an array i.e. the array is re-classified as just holding ELEMENTS.
Array re-classifications are only done one way. Concretely, you can transition an array from SMI
to DOUBLE. However, if you remove all floating point numbers from the array, V8 will not reclass
that array back to SMI. The array will retain it’s classification as a DOUBLE.
The same relation holds true when making a packed array holey. The array will be reclassified as a
holey array. However, if you fill in the holes, V8 won’t go back and classify the array as packed
again. Mathias says that these transitions can be visualized as a lattice (see figure below).
Lattice screen capture from Mathias Bynens’ talk
Try to use arrays over array-like objects. Array-like objects are integer indexed objects with a
length property. Using array-like objects prevents V8 from fully optimizing your code even though
you can use Array.protoype methods via call(). This includes using the arguements object in
functions. Nowadays, you should use rest parameters instead.
Optimizing array initialization vs element kinds
You can initialize an array with the array constructor i.e. new Array(n). This is great if you
know you will have a large array and want the JS engine to pre-allocate space. The downside is
that the array will start out with n holes, which means that array operations won’t be as
optimized as operations for a packed array.
Initializing an empty array and continually pushing onto it will help keep optimizations for array
operations, but this comes at the cost of array re-allocations as the array grows. These
re-allocations can grow slower and slower as the array grows.
Which optimization should you choose? There is no right answer and it’s just a game of trade-offs.
You can optimize for array creation or you can optimize for array operations. It will depend on
your use case.
Key takeaway
“Write modern, idiomatic JavaScript, and let the JavaScript engine worry about making it fast” -
Mathias Bynens